Your System Isn’t Slow. It is Misdiagnosed
Most “slow” systems aren’t suffering from performance issues, they’re suffering from misdiagnosis. Before you add caching or scale your infrastructure, you need to understand where time is actually going. Otherwise, you’re just making a broken system faster at failing.
At some point, every team says the same thing:
"The system is getting slow"
And to respond to that, they do what everyone does:
- add caching
- scale the infrastructure
- optimize a few queries
We don't have anything against that approach and it for that moment it does help a bit. But later on the problem comes back. This time usually much worse. Turns out the above approach was just throwing dirt under the carpet and calling the room clean.
The problem was bigger than just a few unoptiomized queries or lack of caching. The problem itself was misdiagnosed.
The Problem With Calling Something “Slow”
"Slow" may sound like a root cause, but it isn't. Rather it is a symptom, and a vague one at that. Two systems can be "slow" for completely different reasons.
| System 1 | System 2 |
|---|---|
| One has consistent high latency | The other has random spikes under load |
| One is CPU-bound | The other is blocked on external APIs |
| One fails silently | The other retries itself into a collapse |
Treating all of that as “performance” is how teams end up fixing the wrong thing.
The Misdiagnosis Pattern
Here is how it usually plays out:
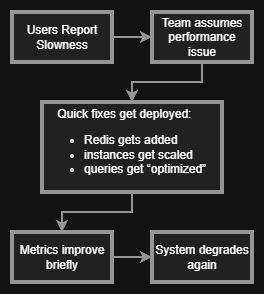
At no point did anyone answer:
Where is the time actually going?
What “Slow” Actually Looks Like in Production
When you dig into real systems, “slow” tends to fall into a few common patterns:
1. Latency Spikes, Not Slowness
This is where everything is working fine, unless someone notices.
A single dependency stalls time, and suddenly requests pile up, timeouts trigger retries, retries multiply load and so on.
Now your system isn’t slow. It is collapsing under its own recovery logic.
2. Queue Backlog Disguised as Performance Issues
Queued jobs aren’t slow. They’re doing what they are supposed to do i.e wait for their turn to get processed. But from user's perspective it looks slow.
What happens in reality is that workers are under-provisioned, tasks are unbalanced or one bad job is blocking everything behind it.
3. Hidden Coupling
Service A calls Service B, which depends on C, which hits D. One small delay here propagates across the chain.
Now everything feels like it is slow, but nothing is individually broken.
4. State Problems
Duplicate jobs. Race conditions. Inconsistent writes. These don’t always crash the system instead they just make it unpredictable. And unpredictability is often mistaken for slowness.
Why Optimization Usually Makes It Worse
This is how people go wrong. They try to optimize before they understand.
So they do what the common knowledge suggests:
- add caching which hides underlying inconsistency
- scale horizontally which multiplies inefficiencies
- introduce parallelism which creates race conditions
The system gets faster in the short term. But also more fragile.
The Real Problem: Lack of Observability
You can’t fix what you can’t see. Most systems labeled “slow” usually have:
- no end-to-end request tracing
- incomplete logging
- no clear metrics on bottlenecks
So teams are forced to guess. And as you might have inferred, guesses don’t scale.
A Better Way to Think About It
Don’t ask:
“How do we make this faster?”
Ask:
“What is the system actually doing under load?”
Speed is an outcome and understanding is the prerequisite.
Final Thought
If you don’t know exactly why your system is slow, you’re not solving a performance problem. As bad as that sounds, but you are guessing. And most systems don’t fail because they were slow. They fail because no one understood them well enough to fix them.
Where We Come In
We’re usually brought in when:
- performance fixes didn’t stick
- scaling made things worse
- or the system behaves differently in production than it ever did locally
At that point, the goal isn’t optimization.
It’s figuring out what’s actually happening, before making it faster at breaking.